The API is King
According to CloudZero[1], most enterprise workflows are now executed in the cloud as of 2024. The average department uses ~87 applications, and the average large company has 371. Most of these services have published and documented APIs and use standards-based authentication mechanisms like bearer tokens or OAUTH2. Many also support login with third-party identity providers following the Open ID Connect standard.
In this reality of ubiquitous, one-size-fits-all connectivity, there is no need to copy, transform, load, and index content into yet-another repository to facilitate a single search across those silos. This is the old way; the new, modern approach is to “federate” the query, sending it out to existing search engines, letting them resolve it, and return results - it becomes game-changing.
Using existing infrastructure is much less expensive than adopting a new silo and copying data into it. A recent study by XetHub[2] proved that it is also maximally effective:
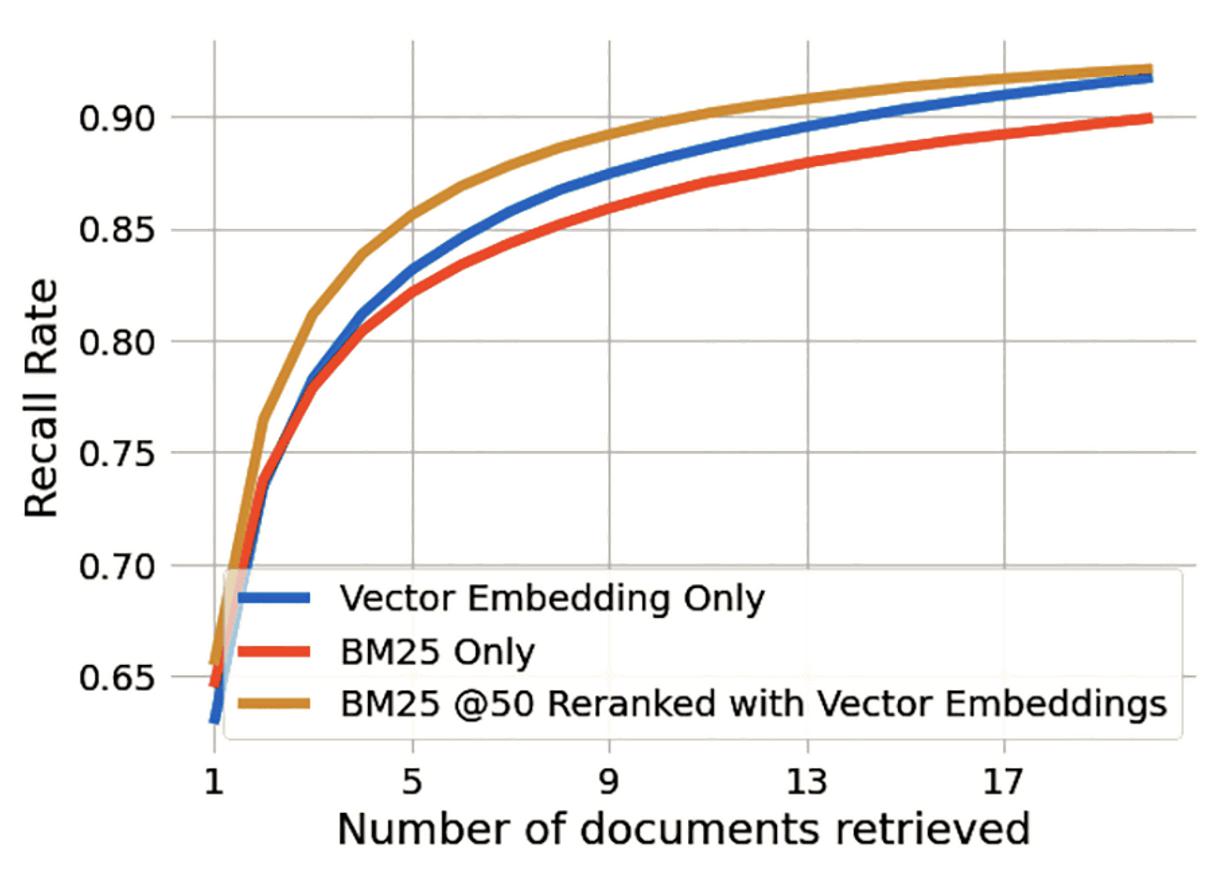
The curve above compares the performance of a classical NLP task: retrieving paragraphs that answer a given question by three systems: “naïve” search implementation relying on “Boolean Match” (BM) in red; a “vector” database in blue; and the combination of using naïve search and re-ranking the results with vectors, in blue.
At the left-most point on the x-axis, where a single paragraph is matched, the BM25 approach is slightly better than the vector database. As the number of results retrieved is increased to 5 results, or 9, the vector database is slightly better than naïve. But the re-ranking immediately pulls away, fully 5% better at 9 or 13 results. This is because naïve search usually has matches; the vector expansion of the query context only works when there aren’t enough exact results. Re-ranking finds these results quickly unless they are truly excluded from the naïve result sets - an uncommon situation. More importantly, many enterprise search engines are doing more than just using BM25; they likely have other ways of accessing business logic - like taxonomies, ontologies, controlled vocabularies, rule sets, etc. These may or may not be present in the vector database’s model.
In the same way - before expecting a Generative AI model to understand or infer internal knowledge, understand that it cannot possibly know about them without being exposed to them in some format. This is the challenge solved by the meta or federated search approach. It becomes possible to access numerous silos safely, using some existing user permission, preserving that business logic, packaging it up, and delivering it to the approved corporate AI. This provides the time-saving benefit of summarization or question answering- in context - without a huge IT project that might break the rules - or bank.
But how do we start setting up a metasearch backbone to harness data for AI across the company? This document presents a reference architecture for doing exactly that.
Reference Architecture for Real-Time, AI-Powered Enterprise Search
The following diagram presents the high-level architecture for using federated search to harness the power of AI using internal data.
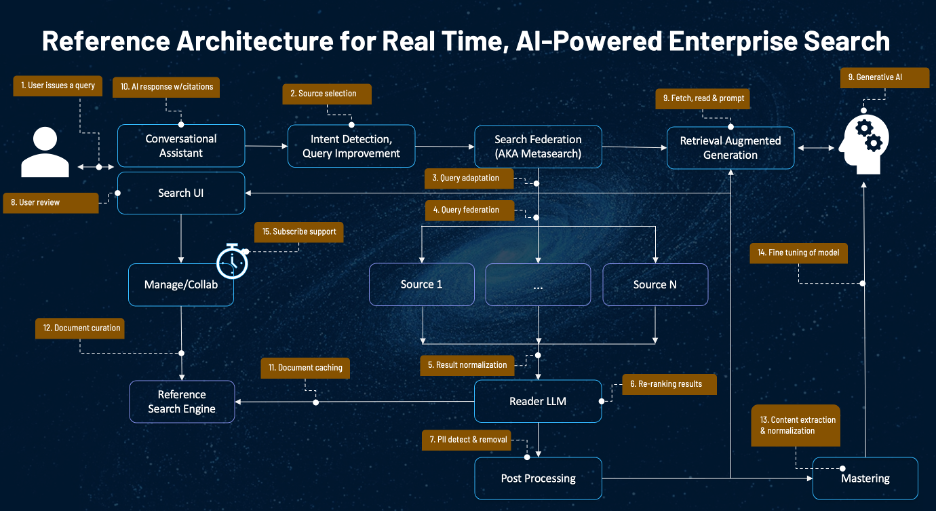
As always, requests for AI-powered search begin with some user. The orange boxes in the diagram above explain how this query is turned into a complete, consumable response - in real-time, without moving or re-permissioning anything!
- The user issues a query. This could be using a traditional search box, a custom application, or a conversational assistant (as shown). The user may specify the sources or set of sources to search, along with other metadata such as the desired data type (most relevant or freshest), etc.
- Source selection. This step involves analyzing the user’s query and identifying (or, ideally, predicting) which source(s) available will be most relevant to the question. There are good reasons not to send every query to every source; for example, this might reveal sensitive internal data (such as an impending merger, legal action, PII, or PHI) to some third party, like an information publisher. The selection model can be driven by AI, machine learning, classification, entity extraction, or processing via an ontology or taxonomy.
- Query adaptation. Not every source is equal; a critical step during the federation process is to adapt the user’s query to the source systems’ retrieval capabilities. For example, this may involve limiting the query to a particular entity type (such as ‘company names’), if a source only knows about those. Or, it might involve adding metadata, such as the field(s) to target or rewriting the query to handle a negated term.
- Query federation. This step involves sending the user’s query to the selected source(s), or the default set if no selections are made. This is typically done asynchronously. The slowest responding API should drive the wait. (Incremental processing is certainly possible, but until all results are retrieved, it is impossible to generate a final re-ranking.)
- Result normalization. Once all of the result sets have been received, they must be normalized into a single schema so they can be compared. This is likely a lightweight schema with < 10 fields. A payload field can carry source-specific information that may interest the user but is not required for ranking.
- Re-ranking results. Once the result sets have been normalized, they can be re-ranked. The range of approaches to re-ranking results ranges from rule-based to using AI. Each of these approaches has strengths and weaknesses. Regardless, the output must be a numeric score that can be used to re-rank the documents.
- Post-processing, including PII removal or redaction. Unless PII is a specific goal for users who search, removal of PII from the search results is frequently a good idea to ensure compliance and avoid data leakage, as described above.
- User review. Once the final, re-ranked result set has been computed, it should be presented to the user in a traditional result format, with metadata such as the count of results from each source. The user should have the option to adjust the rankings - not necessarily numerically, but by determining which results are relevant and which are not. (This feedback can be used with a machine learning model to “learn to rank” over time; this is not shown in the architecture.)
- Fetch, read & prompt. The next step is real-time execution of Retrieval Augmented Generation (RAG) to ground the Generative AI using the top-ranked internal data for the query. Depending on the prompt, the AI can summarize the selected results and/or answer question(s) from them. The RAG process includes three main steps: fetching the full text of each result - authenticating if required; having the reader LLM “read” the full text to identify the most relevant passages; and then binding the most relevant passages to a prompt that is then sent to the configured Generative AI using it’s API.
- AI response with citations. When the Generative AI responds, the insights (“completions”) are added to the search UI so the user can see (a) the selected results, (b) the insight, and (c) the citations connecting (a) and (b). If the user has questions about the summary or results, they may click the links to review the data provided to the Generative AI and determine whether it was correct.
Several additional optional steps can be part of the architecture and generally should be present for large enterprise operations. - Document caching. Storing documents in the federated search system will reduce the source system load and reduce latency and compute costs. However, this creates a potential security issue because the cache must be secured. One approach to avoid this issue is to cache only public documents.
- Document curation. One advantage of a federated enterprise search engine is that the queries are stored in a persistent system. This opens up the possibility of having multiple users share a search object and related results. Given the same permissions, they may curate the results over time and cause a periodic update of the Generative AI summary using, for example, the subscribe feature (see #14). In this way, the solution can be used to create an internal “Wikipedia”, based on internal data, with the individual entries all written by AI using the approved (curated) internal content.
- Content extraction and normalization. As documents are fetched in real-time during the RAG process (#9), they can be labeled, mastered into a standard format, and stored for various purposes. This should include binary format conversion and support for labeling using human-directed and automatic tools such as labeler LLMs.
- Fine-tuning GenAI model. Mastered content can, for example, be used to fine-tune many generative AIs. Using a search-based approach to finding relevant content to train the GenAI is a considerably more effective way to train an AI when compared to feeding it all the content available and hoping it will be able to sort out incorrect, wrong, inconsistent, and outdated information. The reality of messy internal data is the main reason to implement a human review step (#8) in the enterprise - especially if using a commercial
AI that charges per token. - Subscribe support. One of the most potent benefits of the real-time enterprise search architecture is a subscribe feature that periodically checks for new results without the infrastructure to intercept and monitor all sources centrally - and personally, since it always searches on behalf of some user. Subscribers can support a range of use cases - from the traditional cross-silo search alert to regularly updated AI summaries of important topics like competitors, market conditions, or government regulation. These can even be sent to the user’s choice of system - like Slack or Teams - with links to view the underlying data in the relevant applications if they wish to follow up.
Swirling up your Enterprise
Thank you for reading our post. If you want to try Swirl, please visit our GitHub repository at https://github.com/swirlai/swirl-search. We are also available on Azure Marketplace with a 30-day free trial. Please check this page to know more.
And if you need help or support, please join our Swirl community on Slack by following this link: Swirl Community Slack. We appreciate your interest and are here to assist you!
[1] https://www.cloudzero.com/blog/cloud-computing-statistics/#:~:text=Cloud%20adoption%20among%20enterprise%20organizations,this%20survey%20of%20800%20organizations as reviewed 1/8/2024
[2] https://about.xethub.com/blog/you-dont-need-a-vector-database as reviewed 1/8/2024