Cosine similarity is a metric that measures how similar two entities (vectors) are irrespective of their size. Commonly used in high-dimensional positive spaces, it can be helpful in various applications, including data analysis, information retrieval, and understanding the relationship between documents in text processing.
To understand cosine similarity, let's first delve into the basics of trigonometry, specifically the sine and cosine functions.
Trigonometry: A Quick Refresher
- Right Triangles: Imagine a triangle with one angle equal to 90 degrees (a right angle). The longest side is called the hypotenuse, and the other two sides are the adjacent and opposite sides relative to a chosen angle.
- Sine (sin): The sine function is the ratio of the length of the side opposite a chosen angle to the length of the hypotenuse.
- Cosine (cos): The cosine function is the ratio of the length of the side adjacent to a chosen angle to the length of the hypotenuse.
Cosine Similarity: Measuring Angles, Not Lengths
Cosine similarity uses the cosine function to determine the similarity between two items represented as numerical vectors. In this context, a vector means a list of numbers representing an item's characteristics.
The critical concept is cosine similarity, which focuses on the angle between two vectors rather than their magnitudes (lengths).
- Similar Vectors, Smaller Angle: If two vectors point in roughly the same direction, the angle between them will be slight, and their cosine similarity will be close to 1.
- Dissimilar Vectors, Larger Angle: If the vectors point in very different directions, the angle between them will be more prominent, and their cosine similarity will approach 0
- Opposite Vectors: Vectors pointing in opposite directions have an angle of 180 degrees, making their cosine similarity -1.
The formula for cosine similarity between two vectors, A and B, is given by:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Where: - A · B represents the dot product of the two vectors
- ||A|| and ||B|| denote the Euclidean norms (lengths) of vectors A and B, respectively
The resulting value ranges from -1 to 1, with one indicating that the vectors are identical, 0 implying that they are orthogonal (perpendicular), and -1 signifying that they are opposites.
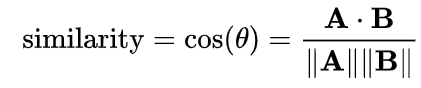
Importance of Cosine Similarity in Text Analysis
Cosine similarity plays a crucial role in text analysis and information retrieval due to its ability to capture the semantic similarities between documents or text vectors. When working with text data, documents are often represented as high-dimensional vectors, where each dimension corresponds to a unique term or word in the vocabulary.
Researchers and analysts can identify documents with similar content or topics by calculating the cosine similarity between these document vectors. This technique is widely used in various applications, including:
- Document Clustering: Grouping similar documents based on their cosine similarity scores, enabling better organization and navigation of extensive document collections.
- Information Retrieval: Ranking search results based on their cosine similarity to the query, providing users with the most relevant documents.
- Recommender Systems: Suggesting items (e.g., movies, books, products) to users based on the cosine similarity between their preferences and the item descriptions.
- Plagiarism Detection: Identifying plagiarism instances by comparing a document’s cosine similarity against a corpus of existing works.
Advantages and Limitations
Cosine similarity offers several advantages, including its ability to handle high-dimensional sparse vectors efficiently and its independence from the magnitude of the vectors (as it considers only the angle between them). However, it also has limitations, such as its sensitivity to vector length and the potential for misleading results when dealing with antonyms or negations.
Despite these limitations, cosine similarity remains a powerful and widely used technique in text analysis and natural language processing, enabling researchers and practitioners to uncover meaningful patterns and insights within large textual datasets.
Conclusion
Cosine similarity offers a nuanced approach to understanding relationships between entities in multi-dimensional spaces. Focusing on the orientation rather than the vectors’ magnitude provides a robust tool for comparing documents, analyzing data patterns, and building sophisticated machine learning and information retrieval systems. Its applications across different domains underscore its importance and versatility in solving various problems.