In modern enterprises, data is often dispersed across various repositories, including applications, databases, data warehouses, and silos. Traditionally, consolidating this data into a single repository for re-indexing has been the go-to method for comprehensive searchability. However, this approach can be both costly and introduce new security vulnerabilities.
Users seek efficient solutions that allow them to locate specific information without the need to manually search through numerous applications and databases individually. Implementing a federated search system offers a secure and cost-effective alternative by enabling simultaneous searches across multiple data sources, providing unified results without the necessity of data relocation.
What is a Federated Search Engine?
A federated search engine is a technology that enables simultaneous querying across multiple, independent data sources through a single search interface. It consolidates results from different repositories - including databases, document management systems, websites, and enterprise applications - while keeping the source data in its original location.
Unlike traditional search engines that require data centralization, federated search maintains data sovereignty while providing unified access.
The Inner Workings of Federated Search
The inner workings of federated search lie in its ability to talk to different data sources, each with its language and rules, and ask them all the same question simultaneously.
The process looks something like:
- You Ask: You type in your search query like in a search engine.
- It Searches Different Applications at Once: The federated search system then uses search provider configuration (in the case of Swirl) and then talks to different indexes and data sources to fetch results from them.
- Databases Respond: Each database searches its records and returns what it finds.
- Results Are Gathered: The federated search system collects all these responses, sorts them out,removes duplicates and re-ranks the combined results.
- You Get Answers: You’re presented with a consolidated list of results from all the queried sources.
Federated Search Diagram
The process looks something like this:
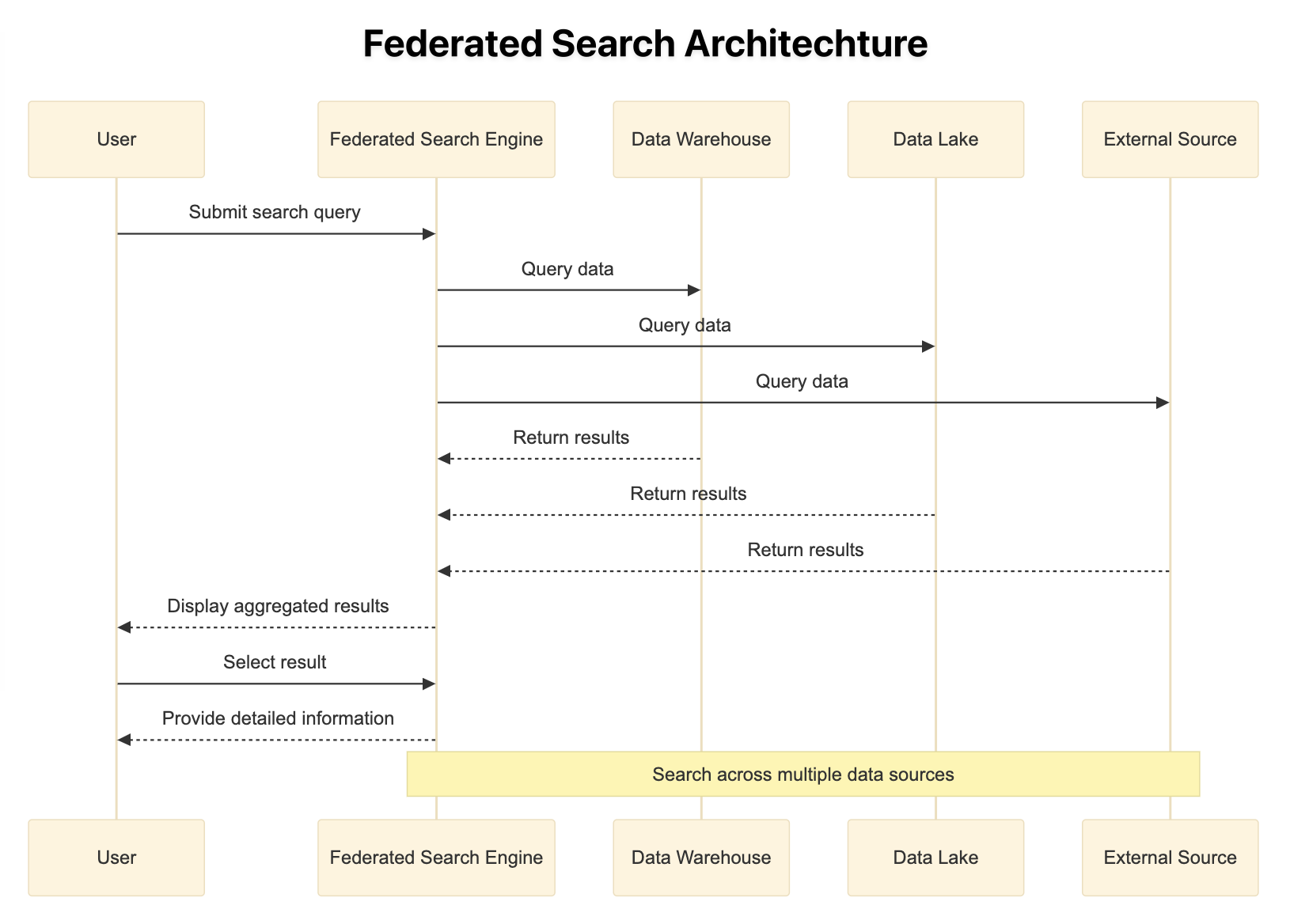
Why is Federated Search a Big Deal?
Federated search is a highly convenient and efficient method of searching multiple databases, websites, chats, internal articles, and repositories simultaneously. Federated search transforms how organizations access and utilize their distributed information assets.
Its significance stems from several key business and operational advantages:
- Time-Saving: No longer need to search through multiple databases, websites or sources one by one.
- Comprehensive Results: Provides a bird’s-eye view of all available information, ensuring that you get all the valuable data.
- Knowledge Discovery: Reveals related information you might not have thought to search for, sparking new ideas
- Improves Business Efficiency: Enables faster decision-making through quick access to information across all sources.
The Future of Federated Search
As organizations generate exponentially more data, federated search is evolving through AI integration. While consumer solutions like Perplexity and SearchGPT demonstrate AI's search capabilities generally on publicly available information, enterprises require secure, private implementations that can securely access sensitive internal data. The next generation of federated search will combine:
AI-Enhanced Search Capabilities
- Natural language understanding for more intuitive queries
- Contextual relevance ranking of search results
- Semantic search across multiple data formats
Enterprise Security
- Private AI models that keep data within organizational boundaries
- Granular access controls integrated with existing security frameworks
Federated Search for your Enterprise: SWIRL
SWIRL is an AI-powered federated search engine tailored for enterprises, offering a secure and efficient solution for unified information retrieval. By connecting to various data sources without the need for data migration or re-indexing, SWIRL ensures real-time access to comprehensive and relevant information.
Key Features of SWIRL:
- Advanced AI Integration: Utilizes Large Language Models (LLMs) to intelligently rank and re-rank search results, enhancing relevance and precision.
- Comprehensive Data Source Connectivity: Capable of searching across a wide array of data sources, including databases, cloud services, and enterprise systems like Microsoft 365, Jira, and more.
- Real-Time Data Access: Employs fetches data in real time using APIs to ensure up-to-the-minute accuracy, making it ideal for environments where data changes rapidly.
- Enterprise-Grade Security: Maintains data within your secure environment, utilizing existing security protocols and offering full Single Sign-On (SSO) support and role-based access control.
- Zero ETL Approach: Processes data in real-time without the need for Extract, Transform, Load (ETL) procedures, preserving data integrity and reducing security risks
By leveraging these features, SWIRL transforms enterprise search and information management, enabling businesses to access and utilize their data more effectively and securely. You can contact us for a 30 day free trial, book a call with us.