A Reader Large Language Model (LLM) is an AI designed to understand and analyze text. Unlike LLMs that generate text, Reader LLMs focus on reading and making sense of existing language. They can be used for tasks like:
- Summarizing long articles or documents.
- Answering questions about a piece of text.
- Identifying the main topic or sentiment of a piece of writing.
Reader Large Language Models are LLMs with fewer layers than a “generative LLM.” They do not create (generate) text. Instead, it is used to “read” text and analyze it.
Reader LLMs can solve a range of interesting problems that don’t benefit from generation of text, such as:
- Similarity - determining the relevancy of one text to others - of variable length, language, syntax, etc.
- Re-ranking - determining which results from a result set are most relevant to a user query.
- Passage detection - determining which parts of a document are most relevant to a user query.
- NLP analysis - such as detecting entities, key phrases, or sentiment.
⠀
Importantly, Reader LLMs don’t “hallucinate.” Since they only use given text, they won’t add new meanings or facts to anything. They have an error rate that depends heavily on the match between the training data and the content to be evaluated. But, overall, the power of modern Reader LLM is massive compared to naive, non-data approaches like search’s venerable TF/IDF.
Reader LLMs are behind many public Retrieval Augmented Generation (RAG) systems… they are used to determine which web page(s) might answer a question are the most relevant and extract the most relevant portions of text from long pages - which are still quite popular. They may also look at the freshness and authority of the link.
Why would a huge web index like Google or Bing need a Reader LLM? Because their extensive web indexes are still indexes - even if they are the largest/most complex ones out there. You can verify this yourself. Try searching Google for “red hat acquires.”
Improving Google’s Search Results with SWIRL’s Reader Large Language Model
“red hat acquires.”
The top results are all about IBM acquiring Red Hat.
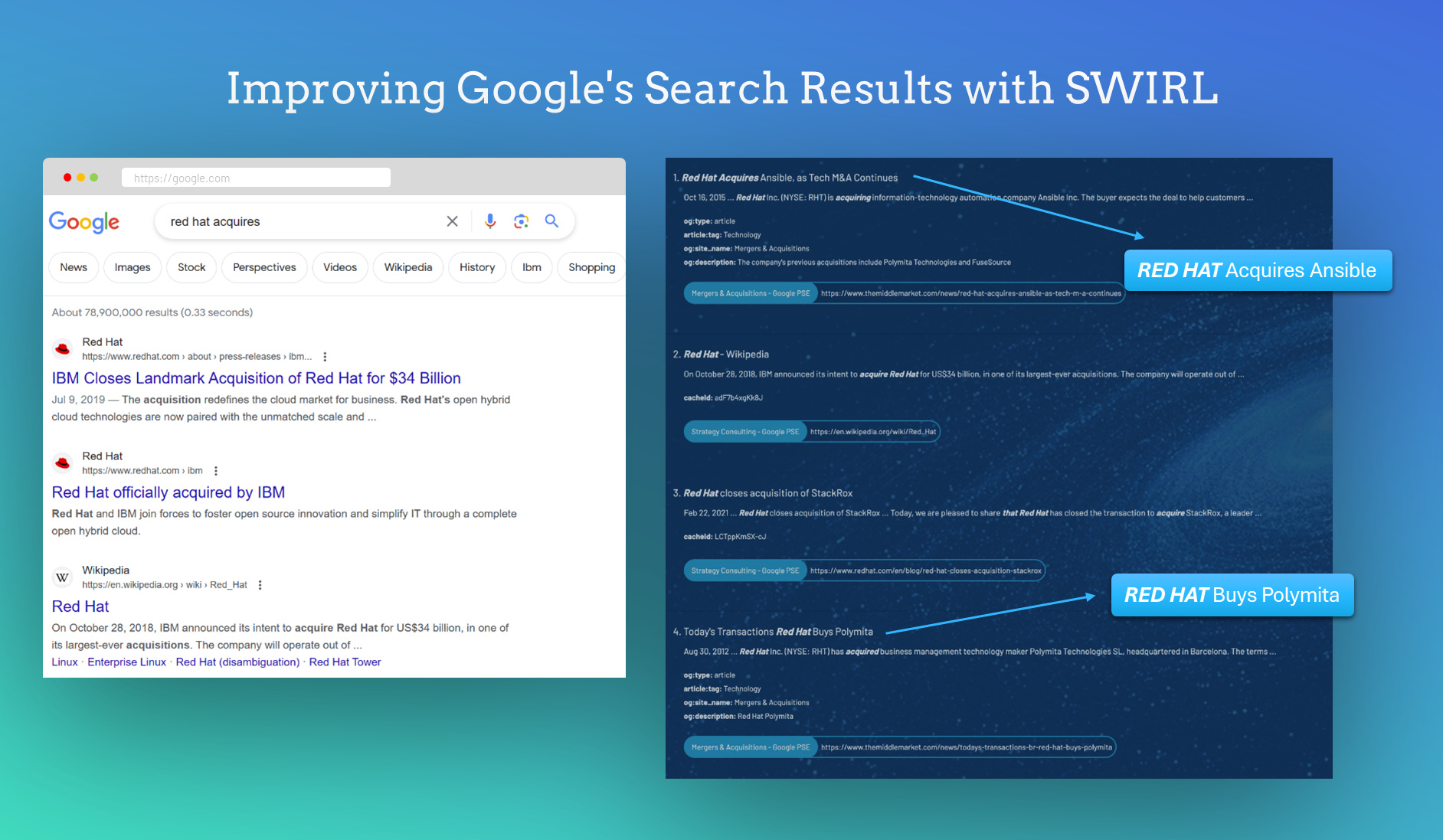
If you re-run this query using SWIRL, you’ll find that our built-in Reader LLM re-ranks Google’s results 7, 8, and 9 - because it cares about word order and knows that “buys” means the same thing as “acquires.”
This leads to an interesting point. There’s no need to move all your data to a vector database, to get good results. The Xethub study, summarized here (https://www.linkedin.com/pulse/vector-databases-rag-simson-garfinkel-hzule/) by Simson Garfinkel, makes it quite clear: it’s better to re-rank results from a fast, cheap index like open search - which can consume millions of documents in a few hours - vs trying to embed everything in a vector database that will be struggling to model 10,000+ in high dimensional space.